
大家好,我是郭建非,是3DNR团队的负责人与 tech leader。
在本文中,我将为大家介绍团队过去一年中围绕「神经渲染技术在自动驾驶领域应用」的一些思考和研究成果。并且向大家展示团队自研的现实级三维重建/编辑/仿真渲染框架——neuralsim 的部分阶段性成果。该框架将在不久的将来完成开源。

自动驾驶传感器仿真,是落地的下一步棋
No.1.1
为什么需要自动驾驶传感器仿真?
近年来,自动驾驶技术发展突飞猛进,很多在实验室中的实验性项目已经逐步走向市场大众。然而时至今日,自动驾驶技术仍然难以做到完全无人,甚至无法保证基本的安全性。究其根本,在于真实道路环境无限丰富,无法被穷举、预测,存在着大量难以预测的边界难例(Hard Corner Case)。
为了解决这个问题,大量自动驾驶公司通过海量路测来提高对边界难例的覆盖率,企图通过遍历这些危险场景来提高自动驾驶系统的实际安全性能。然而,想要通过路测来获得足够多的边界难例,往往需要付出巨大的代价:难例的触发效率呈边际效应递减,而每一次触发都有可能导致一起重大交通事故。
这些客观条件都在限制着我们利用真实车辆在真实世界中完成海量路测和边界难例的覆盖挖掘,而通过「仿真测试」以低成本获得边界难例数据逐渐被认为是解决自动驾驶落地难的不二法门。
早期的仿真测试主要针对决策规划模块进行,然而边界难例不止存在于决策规划系统中,感知系统也仍然存在无穷无尽的边界难例。
2016年,一辆搭载着自动驾驶系统的汽车径直撞向了一辆半挂卡车,驾驶员当场殒命。事后调查分析,自动驾驶系统误以为白色的卡车车厢是明亮的天空,导致避障算法失效并产生灾难性后果。足以窥见针对感知系统的传感器数据仿真有时甚至比决策规划仿真更为重要。

新闻:Details About the Fatal Tesla Autopilot Crash Released (businessinsider.com) https://www.businessinsider.com/details-about-the-fatal-tesla-autopilot-accident-released-2017-6
No.1.2
基于神经渲染的重建、编辑与传感器仿真框架
目前已有诸如 VTD、51 SimOne、NVIDIA DRIVE Sim 等针对感知系统的仿真和测试平台。这些平台大多基于游戏引擎,利用基于物理渲染的传统图形学管线进行仿真渲染。然而,这种传统方法存在一系列问题。
由于图形和当前游戏管线的技术限制,构建超真实的 3D 场景成本高昂,自动化程度低,需要大量人力的介入,且周期较长。针对这个问题,部分方案引入摄影测量等传统 3D 重建技术,来重建真实城市道路场景,但受限于自动驾驶真实数据本身的特点,难以完成全场景的稠密重建和高质量的真实渲染,需要进行人为二次修正和加工。此外,也有通过过程生成等 3D 图形技术,实现自动化生成城市场景的方式,但这种方式同样在复杂性、真实度上都和真实驾驶场景存在较大差异。
为此,3DNR团队(基础算法)联合商汤绝影团队(业务拓展优化),构建了一套直接利用真实车端数据的隐式重建和编辑仿真方案。我们的方案将实车采集的多视图像、激光雷达数据转化为神经网络表示的3D场景库和3D数字资产库,基于隐表面神经体渲染技术,能够渲染以假乱真的相机图像、激光雷达点云,实现「现实级」三维重建和仿真。并且,场景中的要素能够自由地组合控制、轨迹编辑,泛化出新的场景,通过批量仿真渲染,可以产生高一致性的2D/3D传感器数据和2D/3D/4D语义真值标注,以服务于感知系统的测试和训练,迈向自动驾驶数据闭环。我们致力于通过直接实现尽可能全自动的、高一致性的三维重建,大大减少渲染仿真数据与真实场景的领域差异,通过 sim≈real 的思路直接避免 sim2real 的 gap。
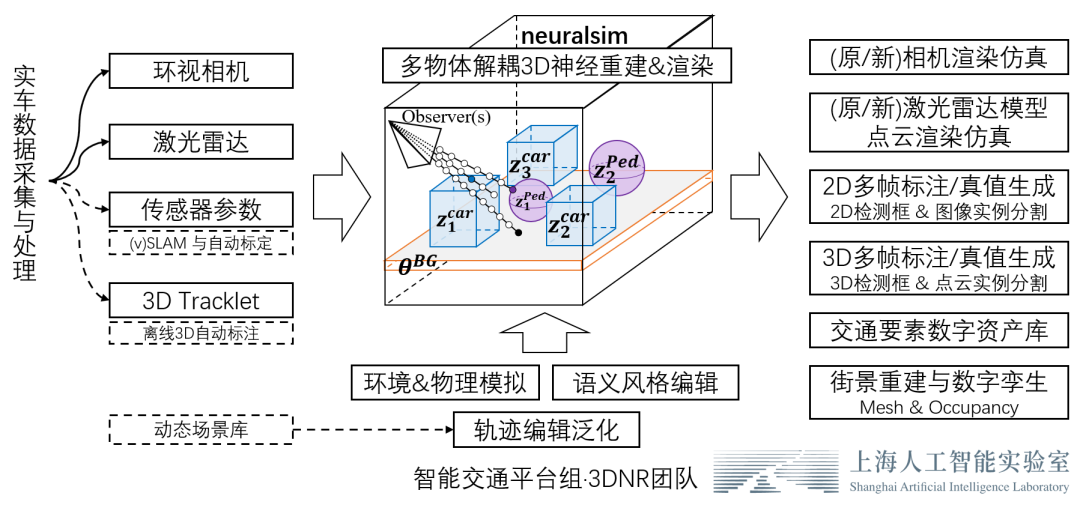
在下文中,我将依次按照「照片级前背景联合重建」「高效的传感器仿真&语义真值仿真」「场景编辑与数据闭环」 三个章节的顺序来介绍我们的工作。


照片级前背景联合隐式三维重建
No.2.1
多帧多模态多视图三维重建
我们可以直接利用实车采集数据,实现对真实街景的前背景联合三维重建。为了方便与学界业界交流对比,我们直接使用 waymo 公开的学术开源数据集 waymo-perception 数据集进行效果展示。
waymo-perception 数据集包含约800个训练集序列,我们挑选了其中3-4个序列进行展示;每个序列长度200帧左右,我们使用序列原始数据中的 前向、左前、右前 3个机位的环视相机图像数据 和 顶部激光雷达数据,以及对应的传感器内外参数据、自车位姿数据进行多视图三维重建。
以 waymo perception - 405841xx 序列为例:

waymo perception - segment 405841xx
原始数据(节选)真值
我们的多视图重建方法主要利用多帧图像数据进行;激光雷达数据主要是为地面的高度和三维结构补充必要的消歧信息,因此并不要求激光雷达涵盖相机的全部视野。对于我们使用的 waymo-perception 数据集而言,在上图中也可以看到,如果将激光雷达点云投射到相机图像中,激光雷达点云只涵盖了图像下半部分的视野。
下面的视频展示了该场景下我们的隐式三维重建的质量和神经渲染的效果。可以看到,我们的方法能够实现以假乱真的三维重建和渲染质量。
如果场景中包含动态要素(如他车、行人),大多数传统的针对纯静态场景的多视图重建工作将不再适用。但是,如果说「没有街景背景不能称作自动驾驶」,那么「没有丰富的前景物体参与交通更不能被称之为自动驾驶」。
因此,我们显式地区分构建了整体的静态背景和动态前景两套3D表征,并设计了一套高效的多物体可微渲染框架。并且,我们通过预先针对前景物体类别构建3D类别先验的方式,解决了前景少视角重建的病态问题,实现了只依赖三维跟踪检测框标注(3D Tracklet)、无需2D图像分割标注,即可对场景中的前景和背景进行联合的隐式三维重建。
以 waymo perception - 767010xxx 序列为例:

waymo perception - segment 767010xx
原始数据(节选)真值
在下面的视频中可以看到,即使面对包含动态前景物体的复杂街景数据序列,我们可以在前景和背景均达到较高的重建质量和渲染效果。
下面的视频中,展示了在更多的 waymo-perception 序列场景下,我们的方法在完整重建后再回放渲染的效果:
No.2.2
背景新视角合成
除了回放再渲染外,验证重建质量的另一个重要方式是新视角合成(Novel View Synthesis)。在下面的视频中,展示了让自车在重建好的场景中自由地螺旋穿梭前进时的多模态传感器渲染仿真效果:
No.2.3
前景新视角合成
不止背景,重建好的前景也可以进行新视角合成,如下图所示:
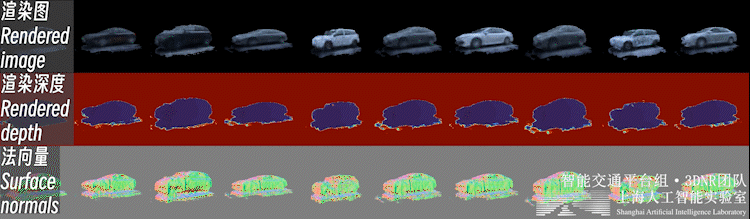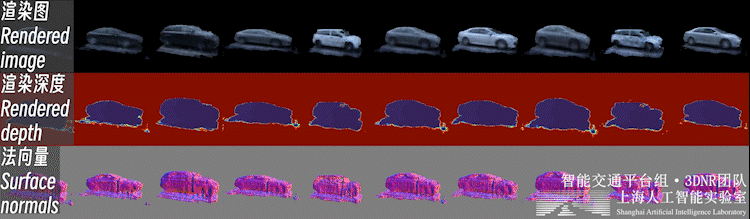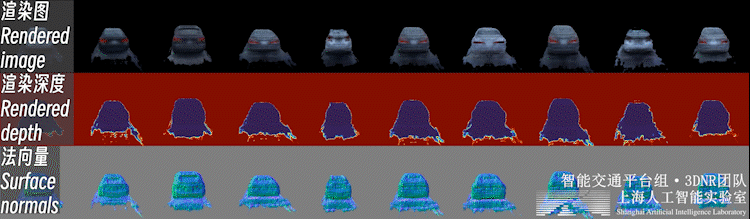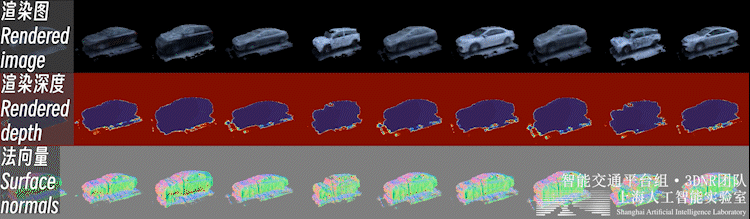
自动驾驶场景下,前景物体普遍面临观测视角少、不均匀的问题。直接对前景物体从头开始(learn from scratch)的三维重建是个高度病态的问题。
因此,我们利用开源类别泛化多视数据集,预先构建了三维生成模型(3DGAN),构建了车辆、行人等交通参与要素的3D形状与外观的类别先验。这样的生成模型可以理解为一个 「实例个数=∞」 的数字资产库(i.e. 每一个随机噪声对应一个独特实例)。
之后,即可利用三维生成模型的逆向过程,在这个数字资产库中可微地 “检索” 出一个符合实际观测的实例,完成少视角重建过程,如下图所示。

在我们的实际应用中,上述前景重建过程和背景的重建是同时进行的。得益于先前构建的3D类别先验,我们的方法能够只依赖3D跟踪检测框标注进行前背景联合重建,而不需要图像实例分割。

高效的传感器仿真和语义真值仿真
不同于 NeRF 原始的体密度 (Volume density) 形状表达,我们选择和拓展了 对仿真编辑和图形引擎更友好的 SDF 隐表面表示 (e.g. NeuS),使得场景的3D几何表示有明确的表面定义和深度概念。
在下图中,我们利用相机对隐表面神经渲染得到的深度,直接对相机2D像素升维得到3D点云,然后将每一帧的相机图像对应的3D点云拼接在一起,进行可视化展示。可以看到,我们的隐表面神经渲染技术具有较高的多视一致性。

利用重建得到的高一致性的3D场景几何与3D场景外观,我们得以仿真高度真实的新传感器的数据。
No.3.1
相机模型仿真渲染
利用重建好的场景,我们可以仿真渲染新的相机模型的图像。在下图中,展示了我们将 waymo 序列原相机的 51° 的视场角逐渐提升到 109°,并加上一定的超广角畸变后,对一个109°视场角的超广角相机模型进行仿真渲染。

No.3.2
激光雷达模型仿真渲染
利用与现实高度一致的场景与物体的3D几何形状,我们可以对不同于原序列的新的激光雷达模型进行仿真渲染。在下面的视频中,我们对重建好的 waymo-767010xxx 序列,仿真渲染8款不同于原序列的激光雷达模型的点云数据。这些新的激光雷达模型包括机械旋转式、固态、棱镜式等多种不同类型。
No.3.3
2D/3D/4D语义仿真
得益于我们设计的多物体渲染框架,我们还能够仿真产生多帧的2D/3D的语义真值标注。
根据相机渲染过程中,逐2D像素对应的3D光线和不同物体3D几何的相交关系和顺序,可以渲染产生图像2D实例分割标注;同理,根据激光雷达渲染过程中,逐LiDAR光束和不同物体3D几何的相交关系和顺序,可以渲染产生激光雷达点云3D实例分割标注。
在下面的视频中,针对重建好的 waymo-767010xxx 序列,展示了我们方法仿真渲染图像、仿真渲染多帧图像2D实例分割标注、仿真渲染多帧LiDAR 3D实例分割 (i.e. 4D语义标注) 的效果:
No.3.4
高效渲染与仿真
我们在神经体渲染底层技术栈中铺设了若干基础建设式的创新。我们吸纳了分层局部隐式神经表征的思想,设计了分块表征与块间连续性保证算法,并利用自举更新的占用格对体渲染中的光线采样过程进行加速。这些创新除了让我们达到前文所展示的重建质量外,还使得我们的神经渲染过程达到接近实时的效率。
下图简单展示了我们的重建方法的分块表征以及可鼠标交互的实时神经渲染:

我们针对前景设计的3DGAN模型同样实现了一套利用占用格的批量(batched)光线采样加速算子,显著提升了前背景多物体联合渲染的效率。

场景编辑与数据闭环
No.4.1
随意的可控显式/隐式编辑
我们的方法将前景和背景都解耦地视作独立的可渲染物体。因此,我们可以对场景中的任一物体模型进行随意的操作和编辑,如下面视频所示:
除了前面展示的针对场景中物体的显式编辑方式外,我们也初步探索了在语义层面的风格化编辑,如下面视频所示:
No.4.2
轨迹编辑与场景泛化
结合动态场景库和轨迹规划算法,我们还可以对场景中的自车和他车进行更符合常理的编辑,即仿真新的驾驶行为。
在下面的视频中,我们依次展示了「左车突然切入(cut in)」,「右车闯红灯」,「前车急停追尾」 3种不同的场景编辑方式,渲染其在 “平行宇宙” 中的虚拟交通事件。
以其中的「左车突然切入(cut in)」场景为例,下面这个视频展示了对编辑后的场景的多模态传感器仿真结果:(相机、深度传感器、8款激光雷达模型)
在今后,我们可以更进一步地利用实车数据扩充3D场景库、扩充前景数字资产库,从而泛化出更多新的物体组合和场景序列。搭配前述 「一次重建、终身受用」的新相机、新激光雷达模型仿真渲染范式,我们的方案最终能够按照给定的场景、给定的物体组合、给定的轨迹、给定的传感器模型定制化地渲染出海量高度真实的传感器数据和语义真值,从而逐渐达成我们构想的通过传感器数据仿真大大提升自动驾驶测试效率和质量的愿景。

写在最后
神经渲染技术作为新兴领域,成功地构建起了场景表征与成像过程之间的可微桥梁,能够很好地结合不同领域的先验知识,使得图像相关的机器学习研究逐渐走向可解释、可控可编辑的3D语义时代。我们坚信,不仅仅是自动驾驶,神经渲染技术将在越来越多的领域走向成熟应用。
我们3DNR团队将继续以自动驾驶数据闭环为理想目标,沿途下蛋挖掘攻关基础学术关键点,并秉持开源和共享精神,与学界业界共同学习共同进步。
此外作为联动,商汤绝影团队也将发表他们的宣传文章,感兴趣的读者还可关注下方公众号名片,阅读商汤绝影团队相关介绍内容。
后续,3DNR团队将进一步介绍分享更多技术细节内容,并陆续发表相关学术论文、开源 neuralsim 等相关项目代码,感兴趣的同学可以持续保持关注、加入我们。沟通交流、简历投递指路:
guojianfei@pjlab.org.cn
文中出现的自动驾驶相关数据集,欢迎到OpenDataLab下载、体验:https://opendatalab.org.cn/。
文章
11.88W+人气
19粉丝
1关注
更多数字孪生可视化干货内容






 扫一扫关注公众号
扫一扫关注公众号
 扫一扫联系客服
扫一扫联系客服
©Copyrights 2016-2022 杭州易知微科技有限公司 浙ICP备2021017017号-3  浙公网安备33011002011932号
浙公网安备33011002011932号
互联网信息服务业务 合字B2-20220090







