上图中,左上角为最高面数的模型,人物脸部光滑精致;右下角为最低面数的模型,已经明显可以看到人物脸部的棱角。
网格的面数越表现效果成正相关,但也与性能消耗成正相关。就是说越多的面数虽然效果越好,但也越消耗性能。所以效果和性能二者之间需要在面数上做出一些权衡,面数是够用就行,不能一味追求多。
2.2.2 权衡面数
那一般模型多少面数是合适的呢?这其实是一个经验问题,是要根据具体情况而定。
例如在一台显卡是RTX3060ti的台式电脑上,也许可以渲染几千万的面数而不掉帧,所以我们可以假设场景中所有物体的面数不能超过4000万。然后根据场景中需要渲染的物体情况,比如说有4000幢楼房,然后就可以推算出基本上每幢楼房的面数要控制1万左右,合计4000万面数,这样渲染这个场景就不会掉帧了。不过实际情况可能复杂,帧率会受到DrawCall、LOD、纹理等诸多因素的影响。所以我们估算的面数其实是一个概数,主要是估算量级。比如说我们加起来总面数在千万级,就基本满帧(或者说有可能优化到满帧)。如果总面数是亿级,超出最高面数一个数量级,基本上不可能满帧。如果总面数是万级,那性能是绰绰有余,就可以考虑增加面数来提高模型精度,进而提供画面表现效果。
另一方面,我们的面数要“划算”,好钢要用在刀刃上。如果是一张人脸的模型,那面数在百万级甚至千万级都是无可厚非的;但如果是桌子上的一只普通的杯子,它可能是作为场景中一闪而过的背景板而已,那这个杯子模型用百万级的面数来表达可就太不划算了。如果这种杯子场景中有几十个,那性能直接就拉满了,更不用说放入其他比较重要的物体了。但换个场景,比如说现在有某个艺术大师设计的巨作“艺术杯”,我们需要做一个场景来展示这个“艺术杯”的虚拟模型,那这个虚拟模型得精雕细琢,务求还原,我们甚至会允许用户把镜头拉到距杯子仅有几厘米的超近距离来观察花纹等细节,那这种模型就算耗费百万级的面数也不为过。
所以面数的权衡是要结合需求和实际场景来具体分析判断。
2.3 材质(Material)
上文介绍了网格的概念,而物体的另一个重要的概念就是材质,我们可以说一个物体有了网格和材质之后,就可以放到场景中进行渲染了,所以说网格和材质是物体最基本的组成要素。
网格是物体形状和轮廓的表达,而材质就是用来在轮廓的基础上进行着色填充。通俗地说,网格好比建筑的梁柱框架,材质好比建筑的砖墙壁画等。所以材质必须依附在网格上,网格需要材质才能进行视觉呈现。



从“材质”这个词语来说,材质可以用来表现例如摩托车头盔的塑料材质、沙发椅子的布料材质、玻璃的盖子和金属的盘子等。
材质能够让3D程序中的物体表现出接近真实物体的色彩,而这些真实感其实得益于一种称为纹理的东西。
2.3.1 纹理(Texture)
通俗地说,纹理其实就是图片,我们可以把常见格式的图片如JPEG、BMP和PNG放到到3D程序中,这些图片就可以作为纹理使用。或者说给材质使用的图片就称为纹理。(实际上纹理的来源不只是图片)
例如下面的分别是砖墙的纹理、木地板的纹理和锈迹斑斑的铁皮纹理。



纹理一般是来自于真实世界中用相机拍摄的照片,所以纹理是足够真实的;然后我们把这些纹理用到材质中,就可以在3D世界中还原比较真实的材质了。
纹理有一个重要的参数就是分辨率,类似于图片的分辨率,或者成为纹理的尺寸。一般我们俗称的4K纹理和2K纹理,就是指纹理的分辨率分别是4096*4096和2048*2048。一般来说,纹理的分辨率越高,材质表现的效果越精致,画面效果也会更好。但和网格的面数一样,越高的纹理分辨率也会导致更高的性能消耗。所以纹理分辨率的权衡与网格面数的权衡是类似的,都是要结合具体情况综合考虑,总之就是要”划算“,够用就行。
2.3.2 贴图(Map)
通俗地说,贴图就是传入到材质中的纹理,传入到材质中的纹理就叫做贴图。贴图的词语重在表达用途,比如说法线贴图,是说它是用于呈现法线的贴图。当某个纹理用于在材质中呈现法线时,这张纹理就叫做贴图,也就是法线贴图。
以下是常见的贴图类型:
a. 颜色贴图(Color Map)
用来表现材质的表面颜色,是最能够直观观察到的贴图,也有的引擎中叫做漫反射贴图(Diffuse Map)。例如下面是一张颜色贴图,它看起是比较平整的墙面。

b. 法线贴图(Normal Map)
用来表现材质表面的凹凸起伏,但它只是一种近似模拟,并没有实际改变网格。

法线贴图一般是五颜六色的,因为它分别用图像中的RGB通道来表示法线向量的XYZ。
下图是上面所示的颜色贴图和法线贴图应用在物体表面后的效果,可以看到,原本平整的墙面上多了很多坑坑洼洼,真实感和细节拉满。

c. 其他贴图
除了上面说的两种常用贴图之外,还有这些贴图:
●AO贴图(环境光遮蔽贴图)
●金属度贴图(Metalness Map)
●粗糙度贴图(Roughness Map)
●环境贴图(Environment Map)
上面的贴图涉及很多进阶的技术,这里不细说。而且还有很多其他的贴图,这里不一一列举。
3 相机(Camera)
相机类似我们拍电影时的用的摄影机,可以拍摄一段动态的视频;或者说类似于我们手机的相机功能,可以拍摄一张张照片。
假设我们要拍一张苹果的照片,我们得先在桌子上放一个苹果,然后我们站在苹果的前方,掏出相机,低头用镜头对准苹果,最后按下快门。
上述过程可以概括成4个步骤:
1 在桌子上方一个苹果 - 2 站在苹果前方 - 3 镜头对准苹果 - 4 按下快门
那回到3D程序的渲染过程中,类比上述的拍照过程,首先得在场景添加一个物体A,然后设置相机位置,调整相机角度,使其面向物体A,最后渲染出这一帧画面。
所以我们定义了一个名为相机的物体,它能够摆放在场景的某个位置,能够调整它面向的角度,它面向的那一面场景将会被渲染到计算机屏幕上。
相机也可以认为是一个物体,它具有几何变换的特征,可以设置位移和旋转(缩放一般是没有意义的)。
3.1 透视投影
我们观察真实世界会发现一种现象,就是同一个物体离得近的时候看着大,离得远的时候看着就变小了,这种现象叫做透视。为了在计算机中模拟透视现象,需要在把场景中的物体在渲染是进行透视投影。
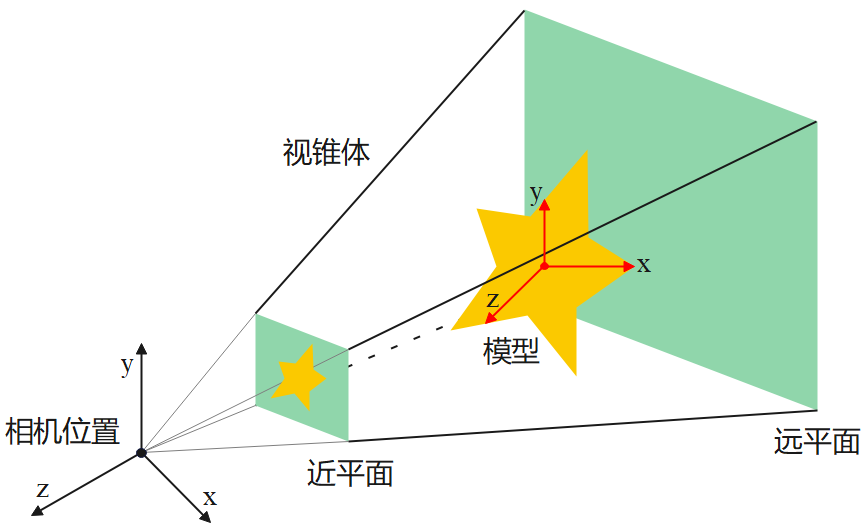
我们先举个投影仪的例子:假设从上图的相机位置放置一台投影仪,从投影仪的发射出呈棱锥体分布的光线。首先光线打在图中标示为模型物体上,然后按照数学和物理规律肯定会投影在图中标示为远平面的画布上。按照透视原理,原平面上会呈现一个放大版的模型的轮廓。这个过程我们成为透视投影。
而3D程序中的透视投影其实是反过来的过程,不是把物体投影在物体之后的远平面上,而是反向投影在物体之前的近平面上(如上图中标示的那个平面)。这个过程也是相机拍照成像的过程,通俗地说就是把世界中的物体投影在相机的感光元件上。
如上图中所示,远平面和近平面以及四棱锥的四条棱构成的形体称为视锥体。视锥体之间的物体会投影到近平面,最终渲染成画面。
能进行透视投影的相机称为透视相机,透视相机的3个主要属性是:
●Near(近平面):表示近平面与相机距离的数值,有时候也简称为近平面
●Far(远平面):表示远平面与相机距离的数值,有时候也简称为远平面
●Fov:表示视锥体的开角角度(就是视锥体对应的四棱锥的那个尖尖的展开角度)
从上文描述的原理我们也可以推断出:与相机距离小于近平面(上文说到近平面是Near这个数值的简称)和大于远平面的物体都将不可见,因为无法投影到近平面上。而Fov越大,能看到的物体就越多,类似于摄影中的广角镜头。
4 光源
现实世界中能看到物体的颜色是因为自然界中光的存在,光照射到物体表面之后,经过一系列反射或者折射进入到我们的眼睛里,这就使我们看到了五彩缤纷的大千世界。
3D程序中模拟了这一过程,使用光源来表现真实世界中的光线,场景的光源有:
●平行光(Directional Light):光线之间都是平行的,也称为方向光,可以用来表现太阳光。

●点光源(Point Light):从一个点向四周发射光线,可以用来模拟小灯泡、蜡烛等点状光源。
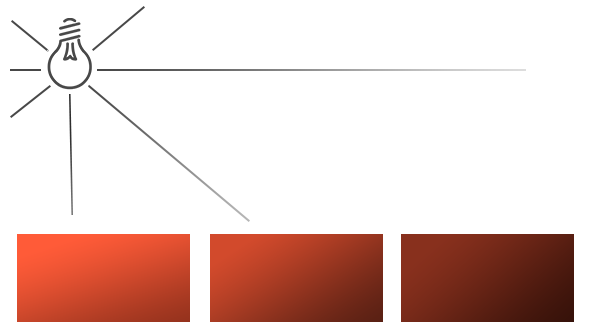
●聚光灯(Spot Light):顾名思义,和舞台上的聚光灯类似,从一个点发出圆锥状分布的光线。
●环境光(Ambient Light):给所有物体一个基础的亮度,使得光源无法直接照射到的地方也能有一些亮度。
综合上文所示的渲染场景必备三要素:有了一个物体之后,给这个物体打上某种灯光,然后设置好相机的位置和角度,就能渲染出画面了。
5 模型
通俗地说,模型就是把3D程序(一般是建模软件)中的某个物体导出成一个文件,然后这个文件又可以导入到别的3D程序(一般是渲染引擎)中,还原成之前的物体。相当于把某个物体打包成文件,就可以在3D程序之间任意传递和共享。这个导出的文件就称为模型。能编辑和导出模型的软件叫做建模软件,例如Maya、Blender和3DMax等。
本质上说一般模型中存储的其实是渲染物体必须的那两大要素:网格和材质,而材质一般会用到纹理;物体一般又会有子物体,子物体之间有相对的空间关系。所以一般模型文件需要存储网格、材质、纹理,除此之外还需要存储物体的层级结构及其几何变换。
5.1 格式
为了能在3D程序之间交换传输,需要约定模型的格式,所以诞生了一些常见的模型格式:
●FBX
●GLTF/GLB
●OBJ
还有很多特定建模软件导出的模型格式,也不一一列举。
而一般的格式都约定了能够存储的材质属性,例如一般的模型格式都能存储上述的颜色贴图和法线贴图,但一些在建模软件的材质编辑器里能支持的节点或节点属性就不一定能够存储在模型中。这样会导致模型导入到渲染引擎中后发现渲染效果和建模软件中差距甚大,尤其是一些玻璃效果。
所以一般PRB材质能够表达的效果,是可以通过模型导出的,其他的高级特效如粒子,或者与环境有关的材质,就不能直接在建模软件中制作,需要在渲染引擎中即时创作。
5.2 模型的几何变换
上面说到模型中要存储物体的几何变换,几何变换都是坐标表示的,有坐标就有坐标系和坐标原点。模型中物体几何变换的坐标系原点就叫做建模原点(通俗的称呼)。
因为模型中的物体是可以偏离原点的,而模型加载到场景中后,一般是以它建模原点的所在的位置作为整个模型物体的位置。而如果模型中的物体偏离原点太多,会导致我们看到的模型形体没有在物体的中心,有时候偏离太大了,超过视野范围了,我们会在场景中看不到这个物体,这就需要在建模软件中正确设置建模原点。
另一个可能导致模型加载后看不到的原因是几何变换中的缩放。就是模型加载进来之后,它比相机的视野范围要大得多,大到超出可见范围,或者说相机当前在模型中央的大空洞之中(模型一般是空心的)。或者模型太小了,小到一像素都没有,所以完全看不见。所以建模软件导出模型时,需要确认渲染引擎中的单位,另一方面,渲染引擎导入一个模型时,要注意模型的单位。
5.3 模型单位
严格来说模型本身并没有单位,它有的只是几何变换的数值。
例如我们有一个身高为170厘米的人物模型,模型中并不会存储“厘米”这个单位,只会存储170这个数字。这意味着这个人物到底多高,取决于导入这个模型的3D程序怎么去“解释”这个170。如果3D程序“认为”这个170的单位是厘米,那导入之后就是能看到正确的人物大小;如果3D程序“认为”这个170的单位是米,那就会看到100倍大小的人物。
一般的3D程序中都有设置单位的方法,预先设置单位后,会把所有导入场景的模型的数值都“解释”成这个单位对应的大小。
但有的引擎或者平台没有设置单位这么一说,其实这就是一种相对大小的思想。就是比如说项目启动后,先约定项目中使用的单位是米,那建模软件中导出的人物模型的身高只能是1.7这个量级的数值范围(例如1.2到2.2),而不能是170这个量级的数值范围(例如120到220)。当只有一个物体时,大小并没有很大的意义,而当导入一幢楼房的模型后,这个楼房模型的高度的数值如果是50这个量级的数值范围(例如10到100),那人物和楼房一比对,发现相对大小是和真实世界差不多的,那就没有问题。所有的模型都按这个单位来导出,那项目中所有的物体的相对大小都是正常的。
如果模型导入到场景中后发现与其他物体相比大小不正常,或者因为单位不对而导致在场景根本看不见,可以调整模型物体的缩放来校正单位的错误。例如把原先单位为厘米的人物模型导入到约定了以米为单位的场景中,就需要缩小100倍才能有正确的大小。
总结
上面大致叙述了3D中的一些基本概念,文中都是比较多通俗的说法,不一定专业严谨,但应该更容易让大家入门。












 扫一扫关注公众号
扫一扫关注公众号
 扫一扫联系客服
扫一扫联系客服





 浙公网安备33011002011932号
浙公网安备33011002011932号