导读
可视化对于Transformer的模型调试、验证等过程都非常重要,FAIR的研究者开源了一种Transformer可视化新方法,能针对不同类呈现不同且准确的效果。
近两年,“Transformer”的热潮从自然语言处理领域席卷至计算机视觉领域。Transformer及其衍生方法不仅是几乎所有NLP基准测试中最先进的方法,还成为了传统计算机视觉任务中的领先工具。在结果公布不久的CVPR2021中,与Transformer相关的工作数量也十分可观。
Transformer Interpretability Beyond Attention Visualization

来自FAIR和以色列特拉维夫大学的学者在CVPR2021中发表了一篇名为“Transformer Interpretability Beyond Attention Visualization”的论文。在这篇论文中,作者提出了一种计算Transformer网络结构相关性的新颖方法,首次实现Transformer的可视化能针对不同类呈现不同且准确的效果。



对于语言分类任务,作者使用基于BERT的模型作为分类器,假设最多512个标记,并使用分类标记作为分类头的输入。对于视觉分类任务,作者采用基于ViT的预训练模型。输入图像尺寸为6*6的所有不重叠色块的序列,线性化图层以生成向量序列。
下图给出了本文的方法与各种基线方法之间的直观比较。可以看出,本文方法获得了更加清晰一致的可视化。
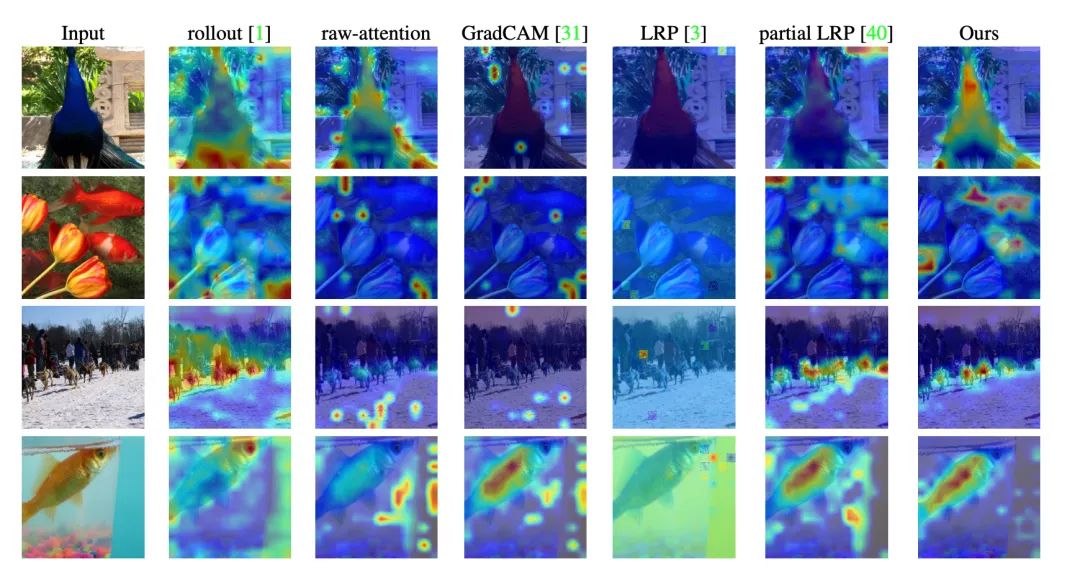
下图显示了带有两个对象的图像,每个对象来自不同的类。可以看出,除GradCAM之外,所有方法对不同类都产生了相似的可视化效果,而本文方法则取得了两个不同且准确的可视化效果,因而证明该方法是特定于类的。

下表为在ImageNet验证集上,预测类别和目标类别的正负扰动AUC结果。

ImageNet分割数据集上的分割性能:

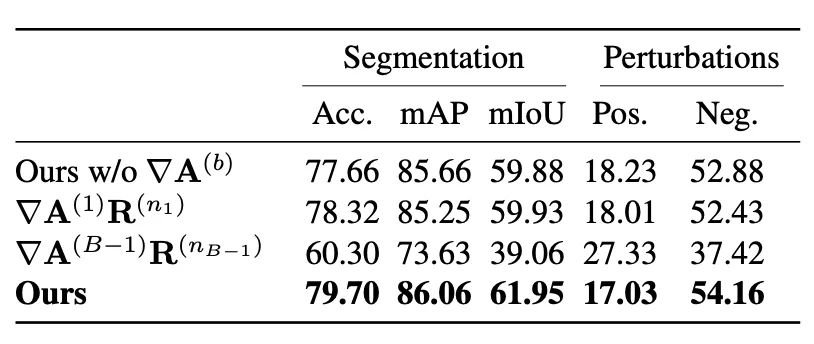
本文方法不同消融方案性能:
文章
13.15W+人气
19粉丝
1关注
更多数字孪生可视化干货内容






 扫一扫关注公众号
扫一扫关注公众号
 扫一扫联系客服
扫一扫联系客服
©Copyrights 2016-2022 杭州易知微科技有限公司 浙ICP备2021017017号-3  浙公网安备33011002011932号
浙公网安备33011002011932号
互联网信息服务业务 合字B2-20220090







