在项目实施过程中,数据接入的工作可以被分为两部分:数据准备和数据对接。所谓数据准备,是指大屏原型稿已确认, 后端开发 或者 数据开发 就可以根据原型来开发对应的接口/SQL语句了。而数据对接,指的是大屏搭建完毕后,前端开发人员为大屏接入相应的数据。
由于数据接入的工作是由两部分人在不同的阶段来进行的,这就会导致后端开发的接口可能无法满足前端的需求,或者即使能满足需求,也存在一些问题,最终导致后端可能需要重新开发接口,造成重复工作。所以,例举了一些数据接入的最佳实践,以此来规范接口的数据格式。
大屏中使用的数据来源一般分为两种,一种是接口,另一种是数据库,两种方式的准备思路一致,表现形式上会稍有区分。
select * from table_aa where type = ':type' --此处的 :type 即是后续提到的入参数据在数据库中的样式:
column1 | column2 |
1234 | aaaa |
2345 | bbbb |
对应数据在前端的表现形式:
[
{ // 数据库中的一行
column1: 1234, // 一行中的某列
column2: "aaaa" // 一行中的某列
},
{ // 数据库中的一行
column2: 2345, // 一行中的某列
column2: "bbbb" // 一行中的某列
}
]常规的API接口,路径、headers、body 都可动态传入,反参可以是更复杂的多层嵌套数据结构
这类数据是指那些不会发生任何变化的数据,比如一些指标数据,或者地图的点位、路线数据,在整个大屏的演示过程中,其值都不会被修改。通常,这类数据不会很多,所以我们可以通过一个接口,来返回所有这样的数据,比如下面这个大屏:

大屏中存在6条纯展示类数据,分别是3条翻牌器数据,1条单值占比图数据,2条地图路径数据,以此分类,我们可以将静态数据整理成如下结构:
[
{
"Indicator": {
"a": "123",
"b": "456",
"c": "789"
},
"percent": {
"num1": 0.37
},
"path": {
"path1": [],
"path2": []
}
}
]当然,如果纯展示类数据量比较大,还是建议根据其功能来划分为多个接口。以上面的大屏为例,我们可以改为通过3个接口来获取这三种数据,而不是在一个接口中将他们一次性返回。
还是以上面的大屏为例,现在我将需求改成这样:当地图下钻到浙江省时,单值占比图需要展示浙江省的a指标,三个翻牌器需要展示浙江省内,b指标排名前三的市(包含市区名称和指标值),那么根据这个需求,我们就可以确定两个接口了。
1.某个省份的a指标。
入参:
adcode=330000 //adcode是指每个省的唯一编码,全国adcode值可参考https://a.amap.com/lbs/static/amap_3dmap_lite/AMap_adcode_citycode.zip
出参:
[{
value:123 //浙江省a指标的值
}]2.某个省份内b指标排名前三的市(包含市区名称和指标值)。
入参:
adcode=330000
出参:
[
{
name:"杭州市", //市名称
value:123 //指标值
},
{
name:"宁波市",
value:123
},
{
name:"温州市",
value:123
}
]对于第二个接口,我们在大屏中可以通过下面这种方式来对接数据。
1.在翻牌器组件中添加一个字段(index),用于标识展示第几名的数据。
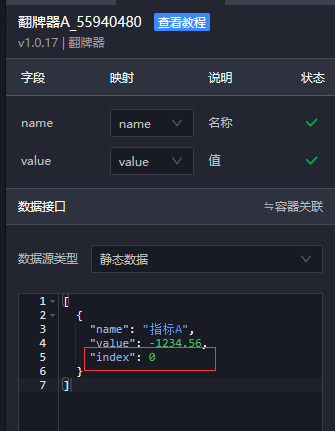
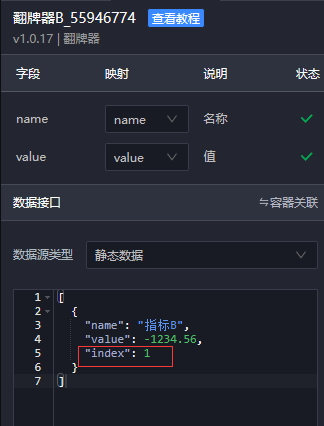

2.用数据容器获取排名数据,然后给数据容器添加回调变量名(test)。
3.编写如下过滤器,接收数据容器的回调,读取翻牌器自带的字段index,根据index来获取对应的数据。
const { test=[] } = callbackArgs; //从回调中提取test数据
if(test[0]){ //先判断test是否为数组
let index = data[0].index; //从组件静态数据中读取index字段值
return [{
...data[0],
value:test[index].value //根据index提取test中的value
}]
}
return data;
拓展:
该案例以adcode作为参数,而不是省份名称,是因为adcode具有唯一性,且编码规则明确,比如全国——100000,省份——xx0000,市——xxxx00,区——xxxxxx。根据这个规则,当我需要全国范围内所有省份的b指标数据时,只需筛选adcode为xx0000的数据即可,当需要某个市内所有区的b指标时,筛选adcode为xxxxxx的数据即可。
继续以上面的案例为基础,我们在大屏中加入一个下拉菜单,该组件用于筛选产业链,产业链选项包括(全部,产业链A,产业链B......),当选择不同的产业链时,需要展示当前省份下,b指标排名前三的市。这时我们需要为接口添加一个新的参数——产业链编码。
入参:
adcode=330000&procode=-1 //procode表示产业链编码,当procode=-1时表示全部产业链。
出参:
[
{
type:"first", //排名
name:"杭州市", //市名称
value:123 //指标值
},
{
type:"second",
name:"宁波市",
value:123
},
{
type:"third",
name:"温州市",
value:123
}
]可以看出,我们的出参并没有发生任何变化,只是入参增加了一个procode。因为对于大屏而言,需要的数据格式并没有任何变化,展示的依旧是某个省份内b指标排名前三的市,只不过增加了一条额外的限制,需要的是某个产业链的数据而已,这个限制是在后端查找数据时进行的,和前端没关系,所以出参格式不需要改变。
另外需求中还有一个隐藏的点,就是需要获取“全部产业链”的数据,正常情况下,每个产业链对应的是一个procode,但是“全部产业链”并不是一个产业链,所以我们需要设置一个虚假的procode作为“全部产业链”,当后端检索到procode==-1时,意味着数据处理结果将和 案例一 一致。
在案例二中,产业链选项是固定的,这也意味着每个procode是存储在静态数据中的。如果每个省份的产业链不同,也就意味着下拉菜单的数据不是静态,而是从接口中获取的,那么此时我们还需要另一个接口,来提供各个省份的procode。
入参:
adcode=330000 //根据地区编码获取该地区的产业链
出参:
[
{
name:"全部",
procode:-1,
},
{
name:"产业链A", //产业链名称
procode:1 //产业链唯一编码
},
{
name:"产业链B",
procode:2
},
{
name:"产业链C",
procode:3
}
]到此为止,我们的大屏交互链路如下所示: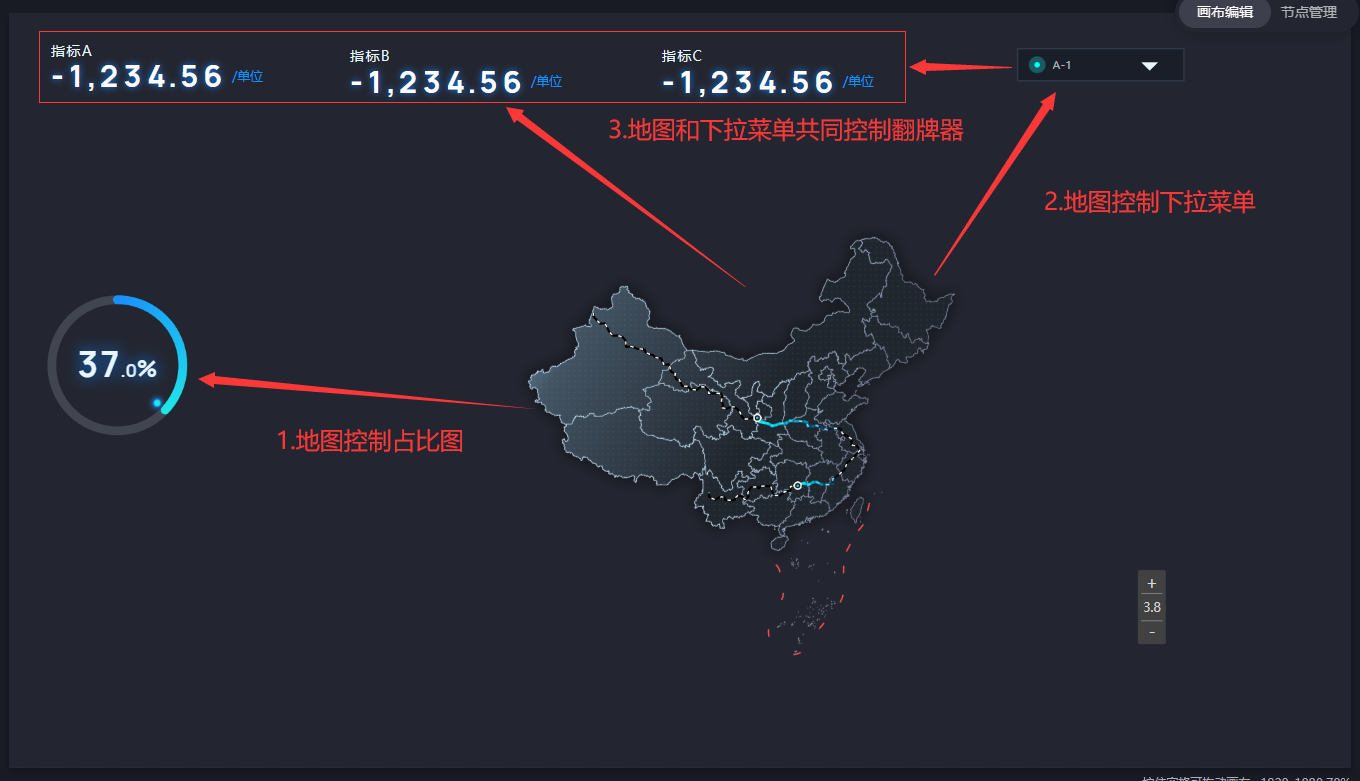
这其实基本符合了大部分大屏的设计思路,一个核心组件(地图),控制其他组件的数据切换;选项类组件(下拉菜单、选项卡等),辅助其他组件筛选数据;最终展示的目标组件做好标记(在翻牌器的静态数据中添加index),便于接受想要数据。总而言之,具体需求具体分析,接口的开发,必须建立在原型的确认之上。
这里只是大致列举,具体的组件数据格式应参考组件的静态数据。
翻牌器:
[
{
name:"名称", //指标名称
value:100 //指标值
}
]
标题:
[
{
text:"名称", //指标名称
}
]
单值占比图:
[
{
value: 0.37
}
][
{
"x": "01/01", //横坐标
"y": 320, //纵坐标
"s": "系列一" //系列名
},
...
]饼图:
[
{
s:"系列一" //系列名
y:123 //数值
},
...
]
选项卡:
[
{
s:"1" //选项下标
content:"选项一" //选项名
},
...
]
轮播表格:
[
{
"column1": "北京", //第一列名称
"column2": 87.2, //第二列名称
"column3": "超预期", //第三列名称
"isSticked": false, //是否置顶
"isSelected": false //是否选中
},
...
]
下拉菜单:
[
{
s:"1", //系列名
option:"选项一" //选项名
},
...
]文章
11.92W+人气
19粉丝
1关注
更多数字孪生可视化干货内容






 扫一扫关注公众号
扫一扫关注公众号
 扫一扫联系客服
扫一扫联系客服
©Copyrights 2016-2022 杭州易知微科技有限公司 浙ICP备2021017017号-3  浙公网安备33011002011932号
浙公网安备33011002011932号
互联网信息服务业务 合字B2-20220090







